Unix Araçları ile REST Api Performans Testi
Geçenlerde canlı ortamda bazı işlemlerle alakalı yavaşlık olduğunu gözlemlemiştik. Sorunun ana kaynağı tahmin edilebileceği test ortamında yakalayamadığımız aşırı yükten dolayı bazı Rest API metodlarının geç cevap dönmesi ya da hata vermesiydi.
Öncelikle Rest API yönetimi için kullandığımız Postman aracı ile bu yükü oluşturup testi yapmaya çalıştım fakat birden fazla iterasyon seçilebilse bile sıralı şekilde bu istekler gönderildiği için herhangi bir sorun oluşturmadı ve API sorunsuz şekilde çalıştı.
Bu aşamadan sonra Postman içinde hızlıca eş zamanlı istek oluşturmaya çalıştım ama böyle bir özelliği ya ben göremedim ya da üründe mevcut değildi, hızlıca baktığımda da kolay bir çözüm bulamadım.
Aslında bu işler için daha önce kullandığım JMeter gibi araçlar daha uygun fakat, ilgili projeyi oluşturup gerekli ayarların yapılması gözümde çok büyüdü, birazda tembellik nedeniyle daha basit bir çözüm arayışına girdim.
Curl ile Rest API İstekleri
Bu da beni en sevdiğim araçlardan biri olan Curl ve arkadaşları ile buluşturdu ve böyle performans testini elimdeki araçlarla yapmak için hızlıca işe koyuldum ve öncelikle senaryoyu oluşturacak, aşağıda basitleştirilmiş hali görülen scripti yazdım.
#!/bin/bash
index="$1"
if [ ! -f "cookie.txt" ]; then
curl -c cookie.txt -s -k --location --request POST 'https://172.16.33.230/api/auth' \
--header 'Content-Type: application/json' \
--header 'Origin: https://172.16.33.230' \
--data-raw '{
"username": "testuser",
"password": "xxxxxxx"
}' > /dev/null
fi
curl -s -b cookie.txt -w "$index:verification %{time_total} %{http_code}\n" -k --location --request POST 'https://172.16.33.230/api/verification' \
--header 'Content-Type: application/json' \
--header 'Origin: https://172.16.33.230' \
--data-raw '{
"data": {
"field1": "value1",
"field2": null
}' -o /dev/null
curl -s -b cookie.txt -w "$index:execution %{time_total} %{http_code}\n" -k --location --request POST 'https://172.16.33.230/api/execution' \
--header 'Content-Type: application/json' \
--header 'Origin: https://172.16.33.230' \
--data-raw '{
"field1": "value1",
"field2": "value2"
}' -o /dev/null
Anlaşılacağı gibi akışımız gayet basit ve aşağıdaki aşamaları içeriyor
- Authentication
- Verification
- Execution
Authentication işleminden sonra bir JWT token döndüğü için bunu Curl ile cookie.txt içine kaydedip ardından gelen işlemlerde cookie.txt kullanarak istek gönderiliyor. Kullanılan parametreleri kısaca şu şekilde
- -c: token içeren cookie bilgilerini cookie.txt dosyasına kaydet
- -b: cookie.txt dosyasındaki bilgileri Cookie header olarak gönder
- -k: sertifika doğrulamayı atla
- -s: işlem ile ilgili durum bilgisi gösterme
- -o: gelen cevabı ekranda gösterme /dev/null a gönder
- -w: istekle ilgili time_total ve http_code değerlerini göster
Bu scripti test.sh olarak kaydedip gerekli yetkiyi verip çalıştırdığınızda aşağıdaki gibi bir sonuç üretecektir
./test.sh "1"
1:verification 1.965970 200
1:execution 0.170458 500
İlk defa çalıştığında authentication yapılıp cookie.txt içinde gerekli olan token kaydedilmiş olacak. Bu örnekte token 15 dakika boyunca geçerli olduğundan ve gerçek senaryo ile aynı olması için tekrar authentication yapmak istemedim, script bloğu içinde if bloğunu görmenizin sebebi bu.
Xargs ile Paralel İşlemler
Buraya kadar tek bir istekle senaryoyu oluşturduk şimdi bunu önce 20’si paralel olmak üzere toplamda 100 istek ve 100 tane paralel olmak üzere toplamda 1000 istek atarak test edelim.
Bizim için asıl önemli olan bu senaryoyu oluşturmada yine sevdiğim araçlardan biri olan Xargs komutunu kullanıyorum. Kullandığım Xargs MacOS üzerinde olduğundan syntax çok az da olsa GNU Xargs komutundan farklı.
printf %s\\n {0..100} | \
xargs -I {} -P20 sh -c './test.sh {}' | \
tee output1.txt
printf %s\\n {0..1000} | \
xargs -I {} -P100 sh -c './test.sh {}' | \
tee output2.txt
Önemli olan parametrelerden bahsedersek
- -I {}: replacestr, yani {} gördüğün yere printf üzerinden gelen istek numarasını koy
- -P100: 100 tane paralel istek ile test.sh dosyasını istek numarası ile çağır
- tee output2.txt: ekrana gelen çıktıyı aynı anda hem ekrana yaz hem de output2.txt dosyasına gönder
- printf: 0’dan 1000’e kadar alt alta sıralı şekilde xargs komutuna gönderilmek üzere istek numarası üret
Yukarıdaki komutları çalıştırıp çıktıyı daha sonra karşılaştırmak için output1.txt ve output2.txt dosyalarına kaydediyoruz. Çıktılar aşadağıki gibi yapılan istek ve numarası, aldığı süre ve http kodunu içeriyor fakat paralel işlemler olduğundan doğal olarak sıralı gelmiyor.
6:verification 36.197475 200
0:verification 36.276390 200
5:verification 36.244690 200
3:verification 36.269677 200
2:verification 37.712106 200
4:verification 37.689079 200
8:verification 37.621507 200
1:verification 37.724796 200
7:verification 38.394440 200
9:verification 38.382456 200
5:execution 14.353162 200
0:execution 14.381653 200
3:execution 14.359871 200
6:execution 14.396236 200
8:execution 25.966200 200
1:execution 25.970524 200
2:execution 25.987604 200
4:execution 26.012512 200
7:execution 25.305976 500
....
Sonuçları Birleştirip Görselleştirmek
Elimizde farklı yük değerleri altında oluşmuş her isteğin numarası, aldığı süreleri gibi verileri içeren iki adet dosya var. Bu dosyaları istek sıralarına göre dizip, aldığı süreleri karşılaştırmak istiyorum ve ardından görsel olarak bir grafik oluşturmak okumak için oldukça faydalı olacaktır.
Bunun için aşağıdaki araçların yardımıyla, toplam istek sayıları farklı olduğu için sadece ilk 50 isteği alan verileri filtreliyorum. Ardından bunlardan stacked bar chart oluşturmak istediğim için yan yana birleştiriyorum.
cat output1.txt | sort -n | awk '{print $1,$2}' | head -50 > dataset1.txt
cat output2.txt | sort -n | awk '{print $1,$2}' | head -50 > dataset2.txt
İsteklerin dosyada sıralı olması için sort komutunu kullanıyorum, bu aşamada HTTP status kodu ile ilgilenmediğimden Awk ile sadece ilk iki değeri yani işlem adı ve aldığı süreyi alıyorum. En sonunda ise ilk 50 isteği almak için head komutunu kullanıyorum Son adımlara yaklaşıyoruz, bu aşamada iki veri setini tek bir dosya altında birleştirip görselleştiricem.
join dataset1.txt dataset2.txt > combined.txt
termgraph combined.txt --stacked
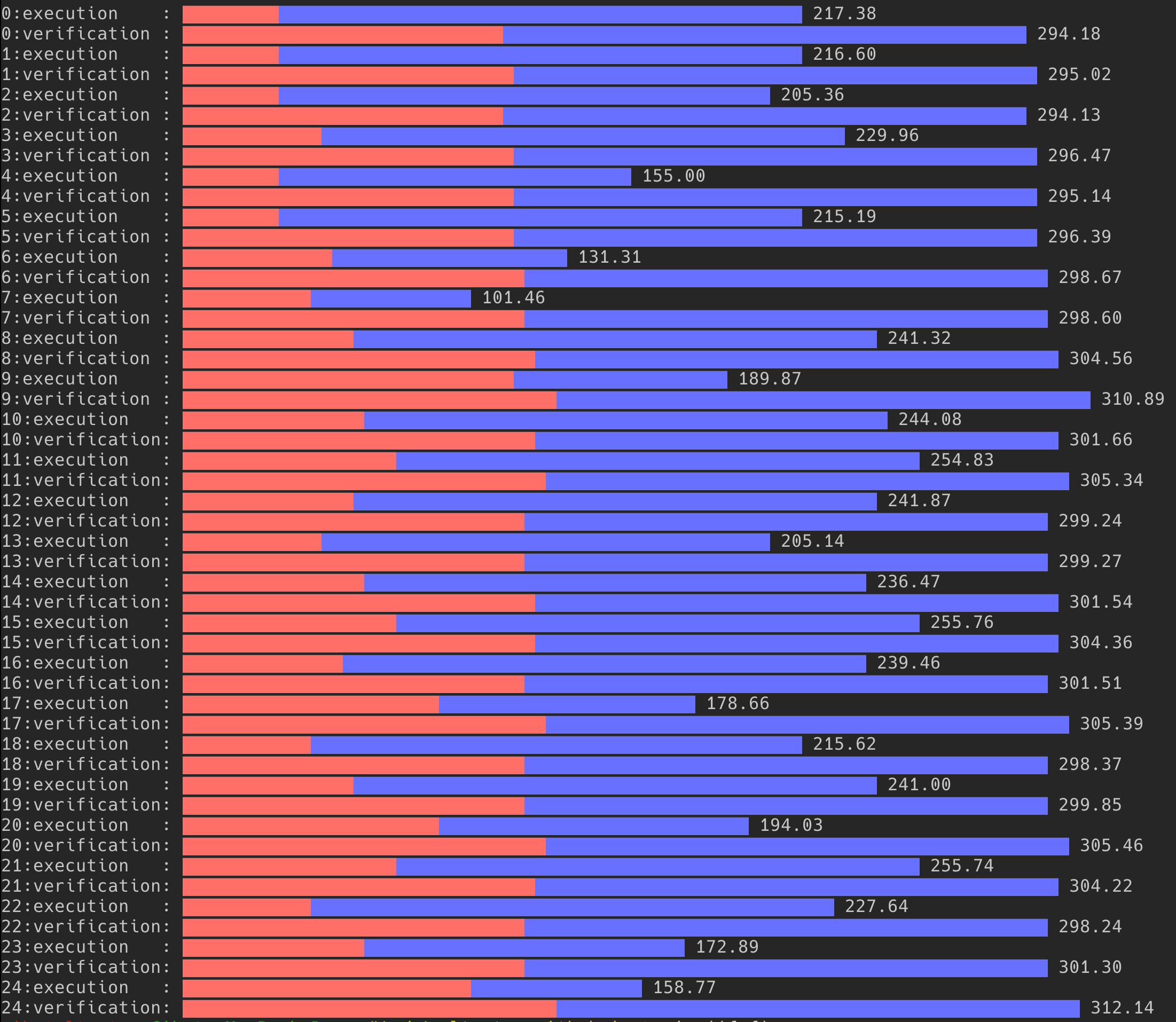
Sonuç
Bence grafik gayet açıklayıcı ve yoğun yük altında sürelerin ne kadar arttığı kolaylıkla görülebiliyor. Bu kadar uğraşa değer miydi? Bence değdi, ilk olarak bu araçlara aşinalığınıza bağlı olarak yukarıda görülenleri çok hızlı bir şekilde yapabilirsiniz. Diğer konu bu script sadece sorunu tespit etmekle kalmadı, sorunu düzeltmesi için çalışan arkadaşa problemi dev ortamında oluşturması için verildi, sorun düzeltildikten sonra test için tekrar çalıştırılıp yapılan performans iyileştirilmesinin doğrulamasını sağladı.
Asıl sorun neydi diye soracak olanlara, kullandığımız Python HTTP Server ve kütüphanesinin async IO ile optimizasyonu yapılarak yoğun yük altında ayakta kalması ve en azından makul sürelerde cevap vermesi sağlandı.